




Working with artificial intelligence (AI) or machine learning (ML) and in need of a text-to-speech engine? If so, you'll require an open-source solution. Let's delve into how text-to-speech (TTS) engines function and explore some of the top open-source choices.
In this straightforward guide, we'll provide more information about TTS engines and present some of the best available options.
What Is a Text-to-Speech (TTS) Engine?
Before diving into the list, let us give you a quick overview of a text-to-speech engine. A text-to-speech engine is a software that converts written text into spoken words. It uses natural language processing (NLP) to analyze and comprehend the written text and then utilizes a speech synthesizer to create human-like speech. You can find TTS engines in various applications, such as virtual assistants, navigation systems, and accessibility tools. If you want to learn more about NLP, DataCamp provides a Natural Language Processing in Python skill track to help you improve your technical skills.
What Are Open-Source Text-to-Speech (TTS) Engines?
Text-to-speech (TTS) engines are software tools that convert written text into spoken words. They are incredibly useful in various applications such as accessibility, automated voice responses, and virtual assistants. Open-source TTS engines, in particular, are developed by a community of developers and released under an open-source license. This means anyone is free to use, modify, and distribute the software without restrictions.
Best Open Source Text-to-Speech (TTS) Engines
Here are some well-known open-source TTS engines:
1. Mimic

Source: Mimic
MyCroft AI has developed Mimic, a speech synthesis system that produces highly natural-sounding speech. It has two versions, Mimic 1 and Mimic 2. Mimic 1 uses Festival Speech Synthesis System and Mimic 2 uses deep neural networks for voice synthesis.
Pros: Offers both traditional and modern voice synthesis methods and supports multiple languages.
Cons: Limited documentation.
Link: GitHub
2. Mozilla TTS
TTS is a library for advanced Text-to-Speech generation. It's built on the latest research and was designed to achieve the best trade-off between ease of training, speed, and quality. TTS comes with pretrained models, tools for measuring dataset quality and already used in 20+ languages for products and research projects.
Pros: It uses advanced technology for more natural speech and is free to use.
Cons: Limited language support.
Link: GitHub
3. Tacotron 2 (by NVIDIA)
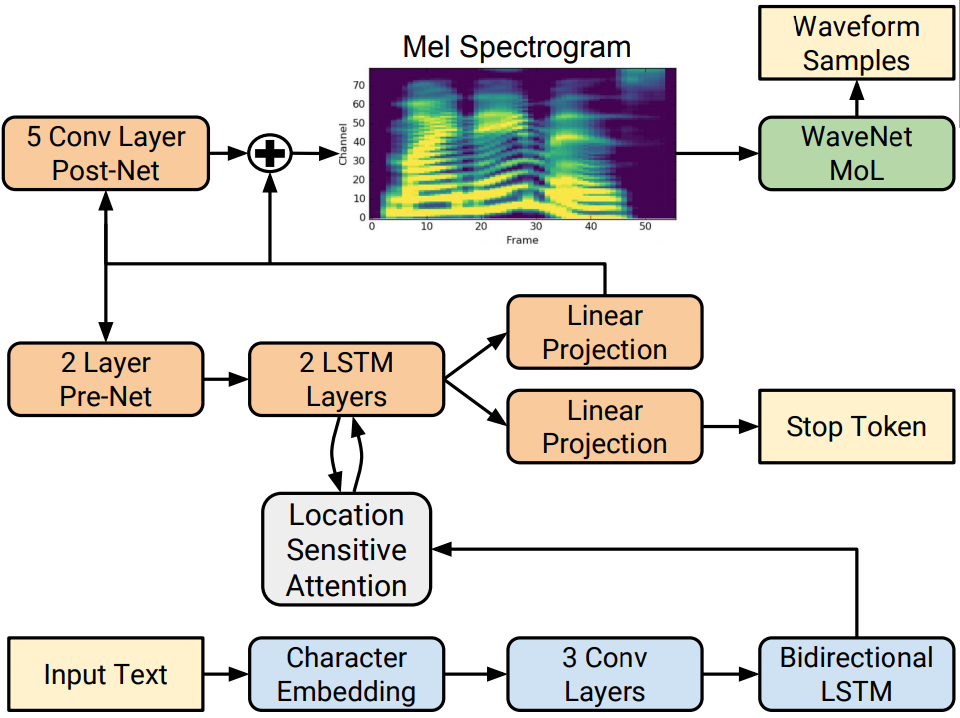
Tacotron 2 is a neural network model that generates natural-sounding speech. Although it is not an engine, it has inspired many advancements in speech synthesis technology, and open-source implementations of Tacotron 2 are available. This system can synthesize speech based solely on written transcripts without requiring additional prosody information.
Pros: Developed by NVIDIA, it is good to be used as a neural network model.
Cons: Requires some technical knowledge to implement.
Although this engine can be technically difficult to master, you can always get familiar with related neural network models through online resources. One such place would be our neural networks guide or our tutorial on neural networks.
Link: GitHub
4. ESPnet-TTS
![]()
ESPnet is an end-to-end speech processing toolkit covering end-to-end speech recognition, text-to-speech, speech translation, speech enhancement, speaker diarization, spoken language understanding, and so on. ESPnet uses pytorchas a deep learning engine and also follows Kaldistyle data processing, feature extraction/format, and recipes to provide a complete setup for various speech processing experiments.
Pros: Modern and flexible, supports multiple languages.
Cons: Requires some technical knowledge to implement.
Link: GitHub
5. MaryTTS (Multimodal Interaction Architecture)

MaryTTS is an open-source, multilingual Text-to-Speech Synthesis platform written in Java. It was originally developed as a collaborative project of DFKI’s Language Technology Laband the Institute of Phoneticsat Saarland University. It is now maintained by the Multimodal Speech ProcessingGroup in the Cluster of Excellence MMCIand DFKI.
Source: MaryTTS GitHub
This architecture includes some basic components such as:
A markup language parser: This component reads and interprets the markup language used in the text field.
A processor: This component takes the parsed text and carries out any required actions, like converting it to speech or creating visual output.
A synthesizer: This component generates the end result, whether it's audio or visual. It enhances the output with speech features, such as intonation and inflection, to make it sound more natural.
Pros: The MaryTTS architecture is highly customizable, enabling developers to create their parsers, processors, and synthesizers to suit their specific requirements. This flexibility also allows for easy software integration into various platforms and applications.
Cons: Developers unfamiliar with markup language and text-to-speech tech may face a learning curve due to its high customizability.
6. eSpeak
eSpeak is a compact and open-source software speech synthesizer that produces clear and intelligible speech in multiple languages. It is well-known for its simplicity and small size. You can run eSpeak on different platforms such as Windows, Linux, macOS, and Android.

Pros: It is simple to operate, and it offers support for various languages and voices.
Cons: It has limited features and customization options. It is written in C programming language.
Link: GitHub
7. Festival Speech Synthesis System
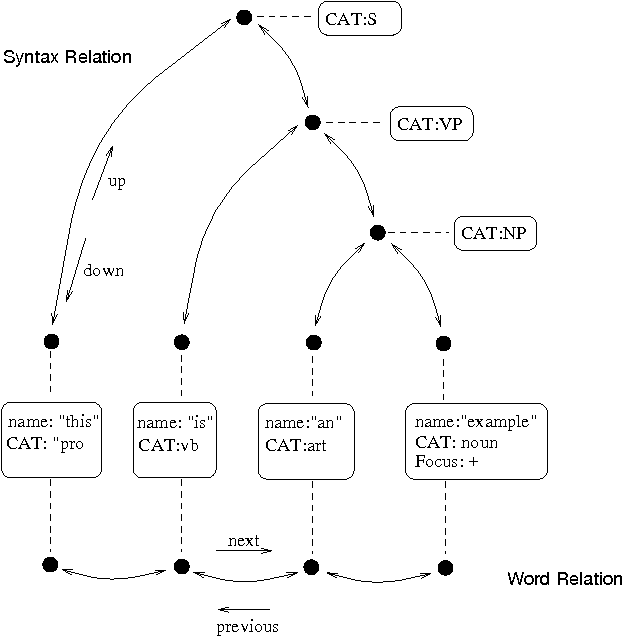
Festival is a speech synthesis framework developed by the University of Edinburgh. It provides a flexible platform for building speech synthesis systems and comes with a wide range of modules for different purposes. Festival is commonly used for research and educational projects. The figure below illustrates the general structure of an utterance in Festival, which is represented as a tree with links between nodes showing their relation.
Pros: Highly customizable, suitable for research purposes.
Cons: It may be challenging for those who are new to it, as it requires some level of coding knowledge.
Link: GitHub
Applications of TTS Engines
Here are some ways the above TTS engines can be used:
1. Virtual assistants
Text-to-speech engines can be utilized to create virtual assistants that are similar to enterprise voice assistants such as Siri and Alexa. Additionally, some virtual assistants can provide accessibility support to users with visual impairments by enabling them to listen to written text instead of reading it.
2. Automatic voice responses with AI voice
TTS engines are commonly used in automated systems, such as phone or chatbot assistants. These engines can provide more human-like responses by reading out prompts and interactions.
3. Video/image voiceover
Text-to-speech technology can be used to bring more life and interest to video or image content. For example, using the eSpeak engine, voiceovers can be added to videos in various languages, making them more accessible and appealing to a wider audience. This is especially useful for industries such as marketing, e-learning, and entertainment.
Choosing The Best Engine for TTS Integration
Let's discuss how to select the right engine for your text-to-speech model. Consider these factors:
1. Purpose and use case
Start by identifying your specific use case and the purpose of using TTS. Understand what features and customization options are necessary for your project, and then choose an engine accordingly.
2. Language support
If you require support for a particular language or multiple languages, make sure to select an engine that offers such capabilities. In that case, going for the eSpeak engine may be a better option for you.
3. Cost and budget
Before selecting an engine, consider your budget and resources. Open-source options may be cost-effective in the long run, but they may require additional resources for customization and implementation.
4. Technical expertise
Evaluate your team's or your own skill level when working with TTS engines. If you lack technical expertise, consider opting for a commercial solution that provides user-friendly interfaces and support.
5. Performance and Quality
It's important to choose a high-quality speech engine that produces natural-sounding audio. Consider testing different engines to find the one that best suits your needs.
Final Thoughts
Text-to-speech technology has improved a lot, sounding more like humans talking. Now, there are lots of free options you can use in your apps, which is good because it's cheaper and easier. But there are also some problems you might face when using these free tools, so it's important to know about them before you decide to use them.