




Text-to-image models didn't exist until deep neural networks advanced in the mid-2010s. However, generative AI has been a hot topic long before ChatGPT. OpenAI's DALL-E, Google Brain's Imagen, and StabilityAI's Stable Diffusion are some text-to-image models that gained attention due to their ability to create images resembling real photographs and hand-drawn artwork. These generative AI models have been a game-changer in the field of AI.
Best 9 Open Source Text to Image Models
So, let’s look at the top 9 open-source image generation models that can help you.
1. DreamShaper
Dream Shaper V7, the popular image generation model based on diffusion architecture, introduces significant improvements in LoRA support and overall realism. It further enhances the features of Version 6, including increased LoRA support, better style enhancements, and improved generation at a height of 1024 pixels (although caution is recommended while using this feature).
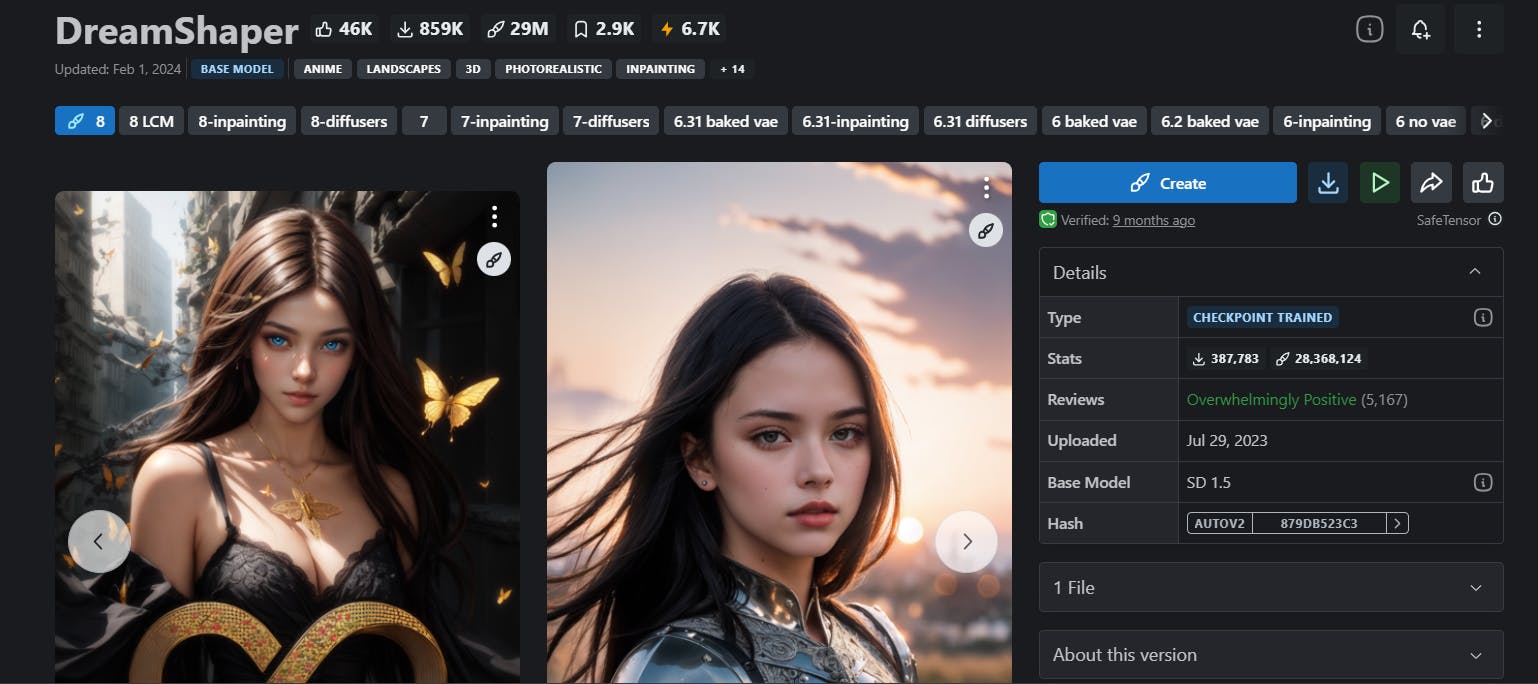
This model delivers photorealistic images with a noise offset, and amplifies anime-style generation with booru tags. It also offers a resolution upgrade for better eye performance, fixing the issues of earlier versions. The impact of Version 3.32's "clip fix" may vary from Version 3.31, and it is highly recommended for mixing purposes. Additionally, it involves inpainting and outpainting, adding to its versatility.
If you want to know more about it, check this out.
2. Dreamlike Photoreal
Dreamlike Photoreal 2.0 is the ultimate photorealistic model designed by DreamlikeArt. It is based on Stable Diffusion 1.5 and offers the best solution to enhance the realism of your generated images by allowing you to incorporate photos into your prompt. For optimal results, it is recommended to use non-square aspect ratios, with vertical aspect ratios being ideal for portrait-style photos, and horizontal aspect ratios for landscape photos. This powerful model was trained on images with dimensions of 768×768 pixels, but it can handle higher resolutions like 768x1024px or 1024x768px with ease.
Running on server-grade A100 GPUs, it outperforms the performance of 8x RTX 3090 GPUs with an average generation speed of just 4 seconds. With the capability to process up to 30 images simultaneously and generate up to 4 images concurrently, this model ensures an efficient and seamless workflow. It includes several features like upscaling, natural language editing, facial enhancements, pose, depth, sketch replication, and many others that make it the ultimate choice for all your photorealistic needs.
You can access it here.
3. Waifu Diffusion

Waifu Diffusion is the ultimate solution for generating high-quality and realistic anime-style images. It is the fine-tuned version (1.3) of the Stable Diffusion model, derived from Stable Diffusion v1.4. The model has proven its worth by producing an impressive variety of images that have gained widespread recognition. The training dataset comprised 680k text-image samples obtained from a booru site, making it the go-to model for generating anime-style images.
Find their GitHub repository here.
4. DeepFloyd IF
DeepFloyd IF is the ultimate solution for generating realistic visuals and language comprehension. This open-source text to image model features a modular design that includes a fixed text encoder and three interconnected pixel diffusion modules. With the ability to generate images of increasing resolution, ranging from 64×64 px to 1024×1024 px, this model is truly cutting-edge.
It utilizes a frozen text encoder derived from the T5 transformer to extract text embeddings that are then utilized in a UNet architecture enhanced with cross-attention and attention pooling. With its impressive zero-shot FID score of 6.66 on the COCO dataset, DeepFloyd IF surpasses all existing models and is without a doubt the best option available.
Check out their GitHub repository here.
5. Stable Diffusion v1-5
The Stable Diffusion v1-5 model is the ultimate solution for generating photo-realistic images from any given text input. It is the most advanced model on the market, combining an autoencoder with a diffusion model and has undergone extensive training on the laion-aesthetics v2 5+ dataset. Furthermore, it has been fine-tuned over 595k steps at a resolution of 512×512 pixels.

Its capability to generate highly realistic images is unmatched by any other model. With the flexibility to generate images from a wide range of latent spaces, this model is not restricted to a fixed set of text prompts. It has been trained on a large image dataset, enabling it to possess a deeper understanding of image characteristics, resulting in the most lifelike image generation possible.
Stable Diffusion v1-5 is accessible in both the Diffusers library and the RunwayML GitHub repository. Check it out here.
6. StableStudio

StableStudio, the open-source AI image generation tool, is the newest release from Stability AI, and it is the ultimate successor to DreamStudio. By utilizing Stable Diffusion models, users can generate AI images through text prompts for free and contribute fixes, new features, and models. Unlike DreamStudio, which was cloud-based, StableStudio is designed to provide more control and customization options, making it the perfect solution for local installation. Pre-built binaries are available for easy installation, and billing and API key management features have been removed. With StableStudio, you have everything you need to generate AI images at your fingertips.
Click here to access the model.
7. InvokeAI
InvokeAI is the forefront provider of Stable Diffusion models for creative engines, offering cutting-edge AI-driven technologies to professionals, artists, and enthusiasts for producing and designing visual media. Featuring a user-friendly interface and a range of advanced tools, including image-to-image translation, out-painting, and in-painting, InvokeAI sets the standard for innovation in this field. It is easy to install and runs seamlessly on Windows, Mac, and Linux systems with GPU cards as low as 4 GB of RAM.
Developed by an open-source network of developers, it is also available on GitHub. If you want to take your visual media to the next level, then purchase the commercial version from the InvokeAI official website today. This version provides more advanced and customizable models, making it the ideal choice for professionals looking to stay ahead of the game.
Click here to access the model.
8. DALL-E mini
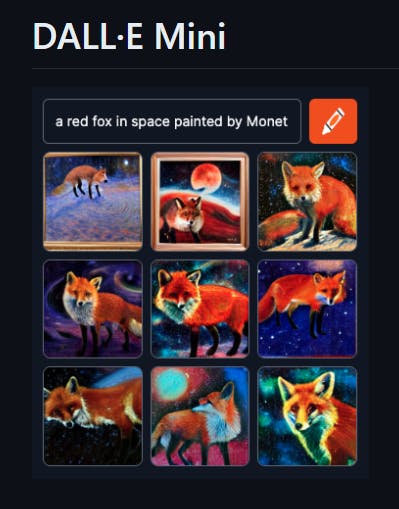
DALL-E Mini is an open-source version of OpenAI's DALL-E that can convert texts into photos or illustrations. With this incredible tool, you have the option to host pre-trained models for text-to-image generation on your own servers, allowing you to use them for personal or commercial purposes.
While the model struggles with faces and heads, the patterns, clothing, and objects look reasonably good in low resolution. However, the creators of DALL-E Mini are constantly working to improve its capabilities, and they now offer a paid online service called Craiyon, which uses a more advanced and larger version of DALL-E Mini, known as DALL-E Mega. With this service, you can expect better results and greater versatility.
Click here to access the model.
9. Pixray
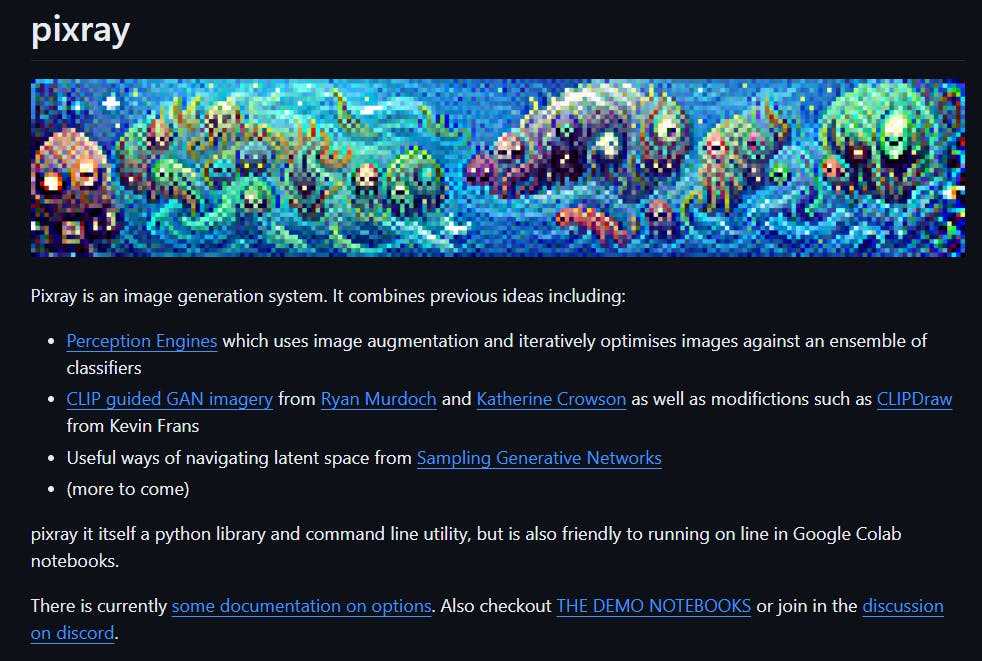
Pixray is a cutting-edge image generation system that employs advanced techniques to create stunning images from text prompts. With an array of powerful features, including the ability to input text prompts, select from a range of render engines (called drawers) such as clipdraw, line_sketch, and pixel, and adjust formatting settings, Pixray offers unparalleled flexibility and control.
The output section displays the generated images along with a time indicator showing the time taken for image generation. To truly unleash Pixray's potential, users can use additional resources such as GitHub, demo notebooks, the Discord community, and documentation. With Pixray, you can create visually stunning images with ease and precision.
Click here to access the model.
Common features
The models implemented in this process utilize foundation models or pretrained transformers, which are large neural networks that have been trained on massive amounts of unlabeled data and can be used for various tasks with the aid of additional fine-tuning. In addition, they employ diffusion-based models, which are generative models that create images by gradually adding noise to an initial image and then reversing the process, producing high-resolution images with fine details and realistic textures.
Furthermore, these models utilize grounding inputs or spatial information, which are additional inputs that guide the generation process to adhere to the composition specified by the user. These inputs can be bounding boxes, keypoints, or images, and can be used to control the layout, pose, or style of the generated image. They also employ neural style transfer or adversarial networks, which are techniques that enable the models to apply different artistic styles to the generated images, such as impressionism, cubism, or abstract, resulting in beautiful and unique artworks from text inputs.
Lastly, these models use natural language requests or text prompts, which are the primary inputs that guide the generation of images. These requests do not require knowledge of or entering code and can be simple or complex, descriptive or abstract, factual or fictional. The models use what they have learned from their training data to generate images that they believe correspond to the requests.